
在现今这个以数据为动力的时代,处理数据的每一个步骤都既复杂又至关重要。这其中,要运用到各种各样的系统和软件,对于新手来说,这些操作往往让人感到困惑不解。这正是我们需要深入研究的难点所在。

系统与软件安装回顾
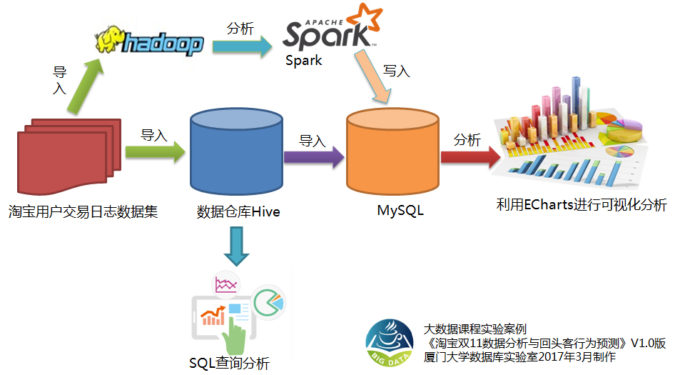
之前已经顺利完成了MySQL数据库、大数据处理平台和Hive数据仓库的部署。在众多项目启动前的环境准备中,这三项工作相当于搭建起了基础。比如,在启动一个创新项目时,团队会首先安装MySQL,确保数据存储的标准化。接着,安装大数据处理平台为处理大量数据做准备,而Hive数据仓库的部署,则为后续数据的特殊管理打下了基础。尽管这些安装步骤在之前的教程中已经介绍过,但它们却是整个数据处理流程的起点。每个系统和软件在安装过程中都有其特定的要求,每一步都需要严格按照步骤进行,否则容易出现问题。
技术人员在进行这项工作时,需熟悉多种技术要点。比如,安装MySQL时,需了解关系型数据库的基本原理;在安装大数据处理框架时,要掌握其整体架构;而安装Hive时,则需明白数据仓库的独特特性和功能。这并非易事,在学习和工作的实际过程中,许多人都会在这一步骤上投入大量时间和精力。
数据集准备
我们使用的数据集是一个.zip格式的压缩包,它收录了淘宝在2015年双11活动前六个月的交易记录。这些数据对于研究当时的淘宝交易状况极为宝贵。压缩包内含有三个文件:用户行为日志文件.csv、回头客训练集train.csv和回头客测试集test.csv。对于一家电商分析公司来说,获得这些数据就像发现了宝藏。然而,在真正分析这些数据之前,还有很多前期工作要做。
首先,我们要对数据进行解压,并创建一个用于运行案例的文件夹。这就像在盖房子前先要整理土地、打好基础。在将数据导入到Hive数据仓库之前,还需要对数据进行预处理。比如,.csv文件的第一行字段名不需要导入,因此需要用脚本将其删除,以确保数据的准确性和导入过程的顺利进行。
cd /usr/local
ls
sudo mkdir dbtaobao
//这里会提示你输入当前用户(本教程是hadoop用户名)的密码
//下面给hadoop用户赋予针对dbtaobao目录的各种操作权限
sudo chown -R hadoop:hadoop ./dbtaobao
cd dbtaobao
//下面创建一个dataset目录,用于保存数据集
mkdir dataset
//下面就可以解压缩data_format.zip文件
unzip data_format.zip -d /usr/local/dbtaobao/dataset
cd /usr/local/dbtaobao/dataset
ls数据截取
head -5 user_log.csv我们需要用脚本从数据集中提取双11的前一万条交易记录,形成小数据集.csv文件。这样做可以降低后续数据处理的难度。比如,在研究数据时,直接处理大量原始数据既费时又可能遇到电脑性能问题。而通过提取操作,我们既保持了数据的代表性,又提高了后续处理的速度。
cd /usr/local/dbtaobao/dataset
//下面删除user_log.csv中的第1行
sed -i '1d' user_log.csv //1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行
//下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了
head -5 user_log.csv在具体的工作环境中,数据挖掘任务中,这样的数据提取显得尤为重要。工作人员会根据项目目标对数据进行挑选,以确保满足特定的分析需求。此外,这一过程还需编写脚本,并严格遵循命令逻辑执行。若任一环节出现失误,都可能造成提取的数据不符合标准。
cd /usr/local/dbtaobao/dataset
vim predeal.sh数据上传到HDFS
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile在将.csv文件数据导入Hive系统之前,必须先将文件传输至分布式文件系统HDFS。这一步骤是本地文件系统与分布式文件系统之间转换的重要环节。我们需先将Linux本地文件系统中的.csv文件上传至HDFS的指定目录。在类似的大数据存储环境中,此类上传任务频繁发生。唯有完成这一上传,才能在Hive中继续对数据进行处理。
先查阅HDFS中.csv文件的前十行内容,这就像在寄快递前核对包裹里的物品清单。这样做能确保数据上传无误且完整,若发现差错能立刻纠正,进而确保后续操作的数据准确性。
chmod +x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv借助MySQL保存元数据
Hive系统依赖某种机制,必须通过MySQL来存储其元数据,因此我们必须先启动MySQL数据库。在数据处理链条中,不同数据库和数据仓库间存在紧密的依赖关系,就好比企业数据管理系统中众多机器零件共同协作。MySQL存储Hive元数据,对Hive的数据处理起到了安全保障的作用。若这一环节出现故障,Hive的数据查询和可视化分析等功能可能会出错,进而干扰整个数据处理流程的连续性和精确度。
cd /usr/local/hadoop
./sbin/start-dfs.sh数据导入到Hive
jps在Hive系统里,我们需要设立两个外部表来导入数据。这个过程就好比在一个精心布置的仓库中安排物品存放。设立外部表需遵循Hive的数据管理规则,输入正确的命令。比如在电商数据仓库管理项目中,准确导入数据是保证数据分析准确和制定销售策略合理的基础。不同的数据导入方法和表创建方法,将影响后续数据可视化和分析的便捷性与精确度。
在进行数据处理的过程中,哪个步骤你觉得最难?欢迎在评论区告诉我们你的感受。同时,别忘了点赞和将这篇文章分享出去。
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
发表评论