
在当今大数据时代,淘宝的双11数据中蕴藏着巨大的商业价值。通过精细处理test.csv和train.csv这两个数据集,我们可以有效地挖掘“回头客”这一重要信息,并将其妥善存储在MySQL数据库里,以便于后续的深入分析。这种做法非常实用。
数据准备上传
在数据准备环节,我已经在 Linux 系统上将数据压缩包成功解压。现在,我需要把 test.csv 和 train.csv 这两个文件上传到 HDFS。通过 HDFS,我们可以更高效地管理和保存大量数据,这对于后续的分布式计算非常有利。这一步相当于为分析流程搭建了一个坚实的“数据仓库”,确保数据能够顺利存储。
[root@centos2020 dataset]# pwd
/usr/taobao_data/dataset
[root@centos2020 dataset]# head -5 test.csv
user_id,age_range,gender,merchant_id,label
163968,0,0,4378,-1
163968,0,0,2300,-1
163968,0,0,1551,-1
163968,0,0,4343,-1
上传完成,我们就可着手进行数据的分析和处理。你可以选用Spark-shell来执行,亦或者将项目打包后上传执行。这两种做法各有利弊,你可以根据你的具体需求来挑选最合适的方法,开启你的数据分析之旅。
[root@centos2020 taobao_data]# vim predeal_test.sh
#!/bin/bash
#下面设置输入文件,把用户执行predeal_test.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_test.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile
test.csv 数据预处理
[root@centos2020 taobao_data]# chmod +x predeal_test.sh
[root@centos2020 taobao_data]# ./predeal_test.sh ./dataset/test.csv ./dataset/test_after.csv
我们需要对 test.csv 数据集进行处理。首先,要剔除那些 label 字段标有 -1 的数据条目。接着,只保留那些用于预测的数据。另外,我们假设这些预测数据中的 label 字段都统一设置为 1。这个过程可以使用 Spark - Shell 或者 Shell 脚本来完成。
[root@centos2020 dataset]# head -5 test_after.csv
360576,2,2,1581,1
295296,2,1,3361,1
230016,5,1,1742,1
164736,3,1,598,1
164736,3,1,1963,1
[root@centos2020 dataset]# head -5 train.csv
user_id,age_range,gender,merchant_id,label
34176,6,0,944,-1
34176,6,0,412,-1
34176,6,0,1945,-1
34176,6,0,4752,-1
在使用 Shell 脚本之前,必须进行授权。脚本运行结束后,你会发现 label 字段都变成了 1。随后,应当去掉脚本的第一行说明,这样做可以提高数据的纯净性,方便接下来的分析工作。
[root@centos2020 dataset]# sed -i '1d' train.csv
[root@centos2020 dataset]# head -5 train.csv
34176,6,0,944,-1
34176,6,0,412,-1
34176,6,0,1945,-1
34176,6,0,4752,-1
34176,6,0,643,-1
处理train.csv文件时,需剔除含有空白字段的数据条目。我们将编写一个专门脚本,脚本会逐行审查数据,一旦发现含有空值的行,便将其筛选掉。
[root@centos2020 taobao_data]# vim predeal_train.sh
去除无用数据,可以使数据后续分析变得更加顺利。这样做能降低因数据缺失而引发的错误或结论不准确的风险。这和整理完房间后工作更高效类似,对数据进行初步整理,同样是为深入分析奠定稳固的基础。
#!/bin/bash
#下面设置输入文件,把用户执行predeal_train.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_train.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile
[root@centos2020 taobao_data]# chmod +x ./predeal_train.sh
[root@centos2020 taobao_data]# ./predeal_train.sh ./dataset/train.csv ./dataset/train_after.csv
Spark 处理数据
文件初步整理后,无用信息已被大量删除。现在,我们可直接使用 Spark 进行操作,无需进行复杂的数据清理。Spark 的处理速度非常快,能高效完成数据分析任务。
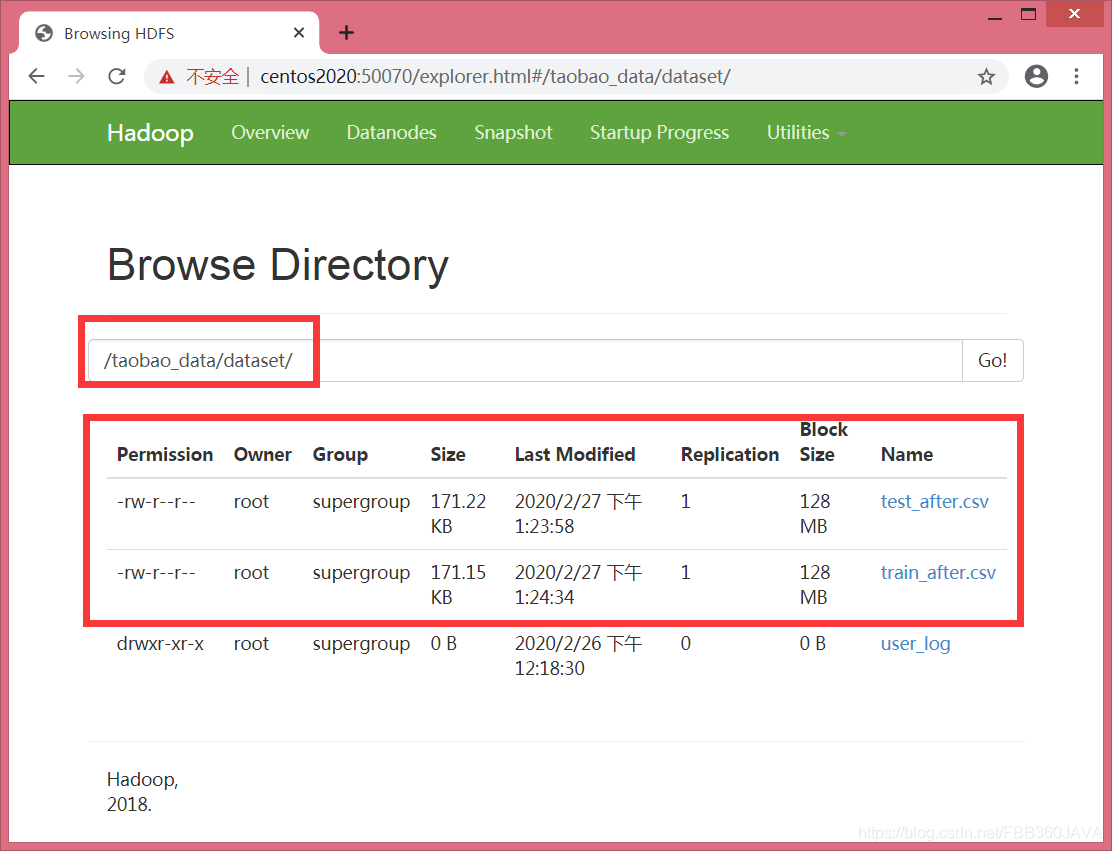
[root@centos2020 hadoop-2.7.7]# bin/hadoop fs -put /usr/taobao_data/dataset/test_after.csv /taobao_data/dataset/
[root@centos2020 hadoop-2.7.7]# bin/hadoop fs -put /usr/taobao_data/dataset/train_after.csv /taobao_data/dataset/
操作完成,您就能直接看到上传后的效果。在开始之前,您需要先找到 mysql 驱动器的存放位置。安装 Sqoop 时,其实已经上传了一个驱动,现在正好派上用场。这是因为我们接下来要用 Spark 把处理好的数据存入 MySQL,而这个驱动器正是连接这两个系统的关键。
[root@centos2020 /]# service mysql start
Redirecting to /bin/systemctl start mysql.service
支持向量机 SVM 预测
mysql> use dbtaobao;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> create table rebuy (score varchar(40),label varchar(40));
Query OK, 0 rows affected (0.22 sec)
在命令行界面,输入代码启动SVM分类器的预测功能,用于对老客户进行分类。使用前,必须导入必要的库,这些库提供了完成任务所需的所有功能和工具。Spark在处理数据时,利用map函数以逗号为界将每行数据拆分,数据集中的每一行被分成五个部分,其中包含标签信息。
我们将把标签和特征数据存放在指定区域,以便后续模型构建。在构建模型的过程中,要将迭代次数设定为1000。同时,还有一些可调节的参数,例如迭代步长和正则化系数等。这些参数的不同配置,将直接决定模型预测的精确度。
[root@centos2020 lib]# pwd
/usr/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib
[root@centos2020 lib]# cp mysql-connector-java-5.1.48.jar /usr/spark/spark-2.4.4-bin-hadoop2.7/jars/
结果存储至 MySQL
[root@centos2020 spark-2.4.4-bin-hadoop2.7]# bin/spark-shell --jars /usr/spark/spark-2.4.4-bin-hadoop2.7/jars/mysql-connector-java-5.1.48.jar --driver-class-path /usr/spark/spark-2.4.4-bin-hadoop2.7/jars/mysql-connector-java-5.1.48.jar
20/02/27 00:37:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://centos2020:4040
Spark context available as 'sc' (master = local[*], app id = local-1582781875708).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
测试集的输出数据要保存在MySQL数据库里。保存好之后,要在mysql里检查数据是否真的存进去了。如果确认数据已经存好,那就说明分析和保存工作都顺利完成了。
在使用支持向量机进行预测时,人们常常会考虑哪个参数对结果的作用最为关键。若本文对你有所启发,不妨点赞或推荐给更多人。
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{Vectors,Vector}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
发表评论